





Тестируем PostgreSQL на SSD RAID-0 массиве с таблицей в 10 миллиардов записей
23 августа 2015

В ходе развития сервиса оптимизации затрат на сотовую связь Dr. Tariff (iOS, Android) для совместного пилота с одним из партнеров нам потребовалась большая и производительная реляционная база данных.
Производительности HDD диска было явно недостаточно. Размер базы должен был составить несколько сотен гигабайт, поэтому размещение ее в оперативной памяти было бы слишком дорого. SSD диск наилучшим образом подходит для этой задачи. Но одного SSD диска могло не хватить, поэтому было решено собрать RAID-0 массив из двух дисков. Пользуясь случаем мы решили провести тестирование производительности PostgreSQL на одном и двух SSD дисках.
Основные цели тестирования
1. Сравнить производительность PostgreSQL на SSD RAID-0 массиве с производительностью на одиночном SSD.2. Изучить производительность базовых операций (SELECT и UPDATE) в зависимости от размера таблицы, количества подключений, настроек сервера и других параметров.
Тестирование проводилось в несколько итераций. По каждой части решено было написать подробную статью с отчетами:
- Тестирование одного SSD диска
- Тестирование RAID-0 массива из 2-х SSD дисков
- Влияние настроек сервера на производительность БД
- Сравнение SSD с HDD
Железная часть
Все тестирование производилось в следующей конфигурации:- Intel i7 4770.
- 16 Gb RAM.
- Intel SSD для системного диска.
- Intel SSD 480 Gb 530 серии для диска в с базой данных. Model – SSDSC2BW480A401
- Toshiba HDD 3000 Gb. Model – DT01ACA300
- Файловая система всех разделов – Ext4. Диски подключены по интерфейсу SATA 3.
Софт
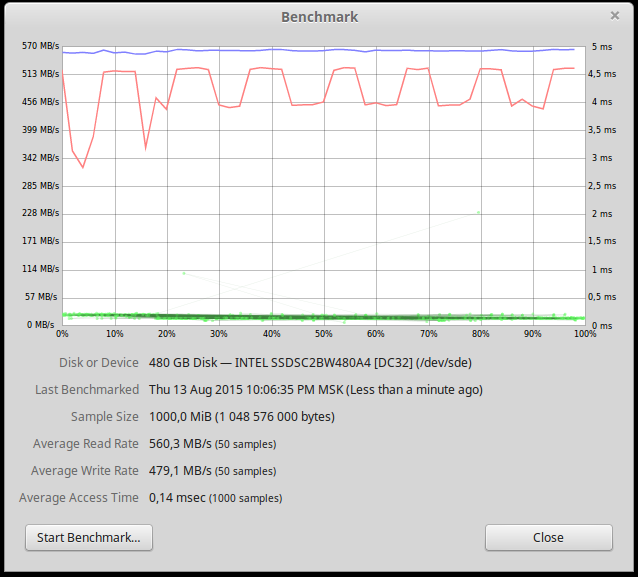
На тестовом компьютере установлена операционная система Linux Mint 17.2. Версия PostgreSQL - "PostgreSQL 9.4.4 on x86_64-unknown-linux-gnu, compiled by gcc (Ubuntu/Linaro 4.6.3-1ubuntu5) 4.6.3, 64-bit"После форматирования на SSD диске доступно 440Гб. На графике ниже представлена производительность одного SSD диска.
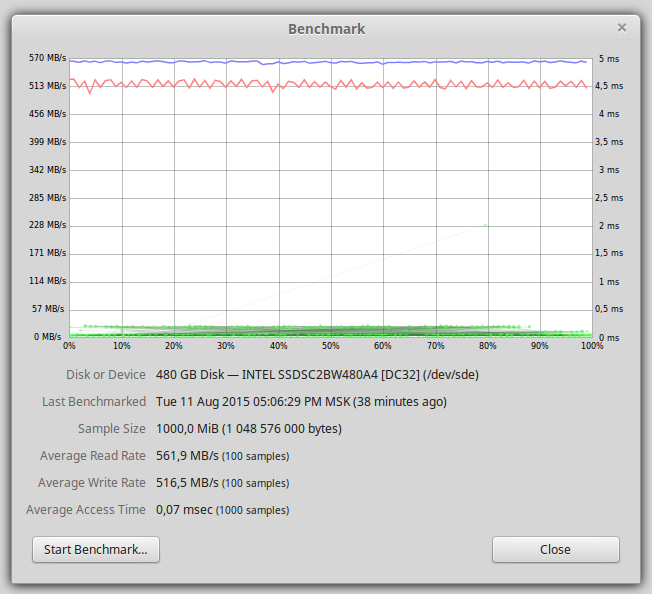
Производительность чтения и записи около 500 Мб/сек, узким местом является SATA интерфейс.
Настройки Postgres стандартные за исключением следующих параметров:
shared_buffers = 2048 Mb
port = 5400
max_connections = 1000
Тестирование
В качестве источника нагрузки было 3 варианта:- стандартный pg_bench
- Python клиент с Psycopg2
- Python клиент с SQLAlchemy
Первым кандидатом в качестве клиента был SQLAlchemy. В нем есть возможность вызова сырых SQL команд через метод execute. Первые же тесты на маленькой выборке показали, что SQLAlchemy потребляет много (десятки процентов) CPU.
При тестировании Psycopg2 клиента потребление процессора было в районе 15%, что вполне приемлемо для тестирования, так как узким местом в большинстве случаев была дисковая подсистема. Все дальнейшие тесты были произведены с использованием Python клиента c Psycopg2. На каждое подключение к БД создавался отдельный Python процесс.
Схема тестовой таблицы:
CREATE TABLE numbers
(
"number" bigserial NOT NULL,
operator smallint,
region smallint,
CONSTRAINT numbers_pkey PRIMARY KEY (number)
)
Для тестирования чтения использовалась команда:
'SELECT * FROM numbers WHERE number=%d'
Н омер выбирался случайный.
Для тестирования записи использовалась команда:
'UPDATE numbers set region=%d, operator=%d WHERE number=%d'
Все параметры случайные из допустимых диапазонов. UPDATE читает и пишет данные на диск при этом не изменяя размера БД, поэтому было решено использовать его для комплексной нагрузки на запись. INSERT и DELETE при тестировании не использовались. Каждый отдельный тест выполнялся несколько минут. Отдельные тесты запускались по несколько раз, и полученная производительность совпадала с точностью около 1%.
Для создания RAID-0 массива использовался mdadm. RAID создавался с использованием всего диска, а не поверх разделов.
Для записи большого количества строк использовалась функция COPY. Данные предварительно записывались во временный файл, а затем импортировались в базу. При таком подходе 1 миллиард записей заносился в базу чуть более 1-го часа.
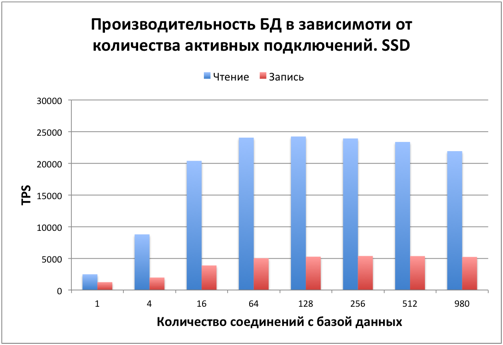
Тестирование производилось на одном SSD диске сразу после заполнения БД. Размер таблицы – 1 миллиард записей. На диске 42Гб было занято под таблицу и 21Гб на индекс. Узким местом является дисковая подсистема. Рассмотрим, как меняется производительность БД в зависимости от количества активных подключений.
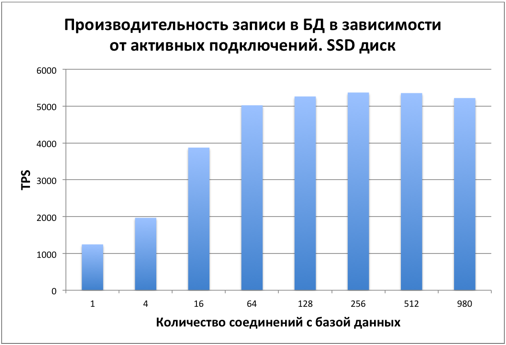
Производительность SELECT
Сначала производительность растет равномерно в зависимости от количества подключений. Начиная примерно с 16 подключений общая производительность стабилизируется, упираясь в диск.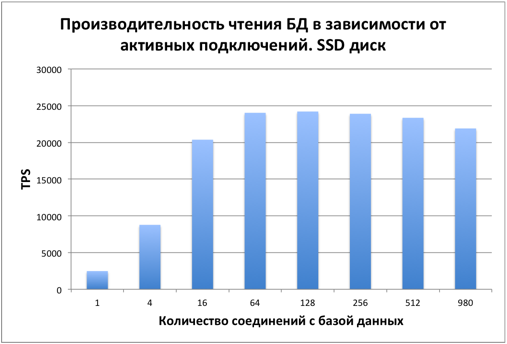
Производительность UPDATE
При обновлении записей картина аналогичная. С 16 пользователей производительность стабилизируется. Узкое место – диск.PostgreSQL использует MVCC для обеспечения ACID. Этим в частности объясняется, что при изменении значения одного столбца во всей таблице размер этой таблицы изменяется примерно в 2 раза.
После обновления многих записей в таблице и индексах стало много dead-записей, что влияет на производительность. Рассмотрим, как это повлияло на производительность чтения.
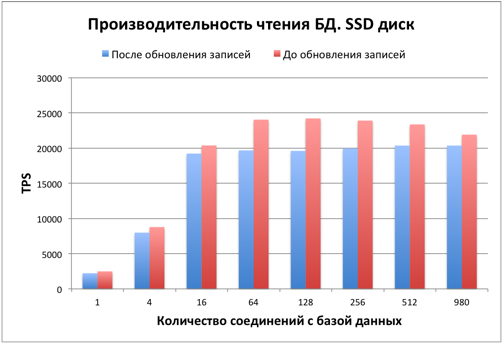
Как видим производительность чтения упала на 15-20%. Также база незначительно увеличилась в размерах. Для увеличения производительности и освобождения занятого места требуется выполнение команды VACUUM. Данный вопрос выходит за рамки статьи, более подробно о нем можно почитать в документации.
После проведения всех тестов и остановки PostgreSQL мы решили повторить тест на скорость чтения с диска.
Как видим, производительность записи на диск упала. Данный график стабильно воспроизводился при различных размерах считываемых данных. Объяснений этому у нас нет. Будем рады, если кто-то объяснит причины падения скорости.
Резюме
Из данных тестов видно, что база данных хорошо работает на SSD диске при количестве записей в таблице до 1-го миллиарда. Приятным результатом стало то, что производительность базы данных практически не уменьшилась даже при 980 активных подключениях. Скорее всего много активных подключений будут потреблять больше оперативной памяти и процессора, узким местом при количестве соединений менее тысячи является дисковая подсистема, но это тема отдельной статьи.Часть 2
Протестируем PostgreSQL на RAID-0 массиве из двух SSD дисков. RAID массив собирался с помощью mdadm. Размер страйпа (блока информации, который распределяется на все диски массива) – 512k.Нагрузка на диски мониторилась с помощью команды iostat (пакет sysstat). При тестировании на одном ssd диске утилизация диска составляла 95-100%. При тестировании на RAID массиве утилизация каждого из дисков в среднем была 90%. Нагрузка на процессор измерялась с помощью htop. Во время большинства тестов, если не оговорено иное, нагрузка составляла 30-50%. Python-клиент, с помощью которого нагружалась база данных запускался с этой же машины и до 20% процессора потреблялась им. Таким образом, производительность системы упирается в скорость работы диска.
Benchmark
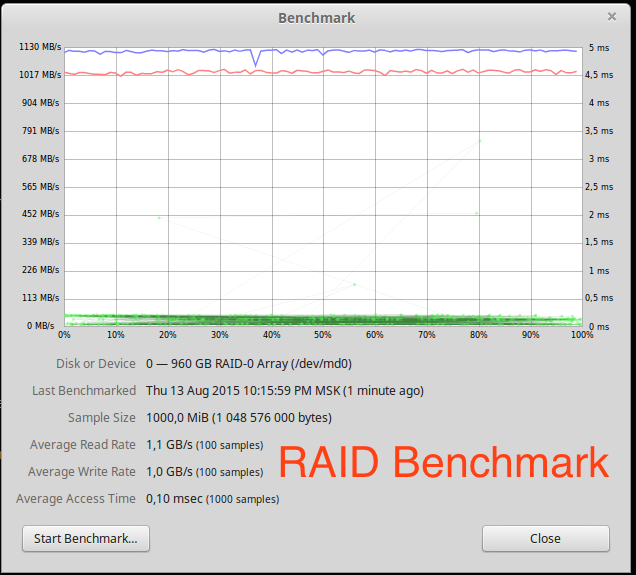
Скорость линейного чтения почти в два раза выше, чем у одного диска. Масштабирование почти линейное для двух дисков.
Производительность PostgreSQL на RAID массиве
Размер и настройки БД точно такие же как в первой части.Производительность чтения

В среднем производительность чтения оказалась на 15% выше, чем для отдельного диска. Это объясняется различной задержкой при чтении случайных блоков. Утилизация каждого из дисков по iostat доходила до 90%, хотя при тестировании одиночного диска она почти всегда составляла 100%. На хабре есть отличная статья на эту тему.
Производительность записи
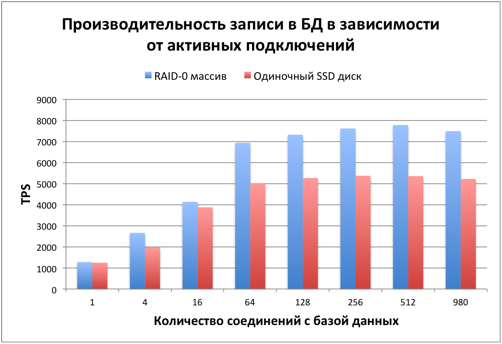
Скорость записи уже на 40% выше, чем у одного диска. Это сильно лучше, чем чтение, но еще далеко до линейного масштабирования, при котором скорость должна быть в 2 раза выше.
Нагружаем диски. 10 миллиардов записей
Время нагрузить диски и базу данных. Тестовый размер таблицы – 10 миллиардов записей. На диске сразу после заполнения 423 Гб было занято под таблицу и 212 Гб на индекс. Процесс заполнения БД занял около 14 часов.Первым интересующим вопросом стало падение производительности при увеличении количества записей в 10 раз.
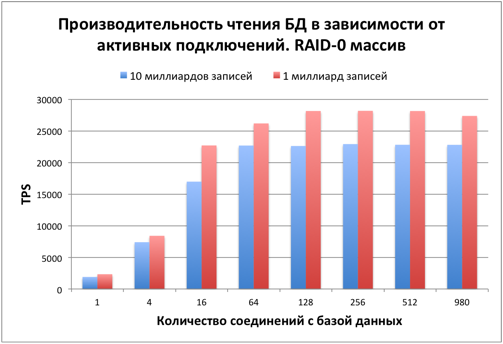
Скорость чтения уменьшилась примерно на 20% в сравнении с БД с 1 миллиардом записей.
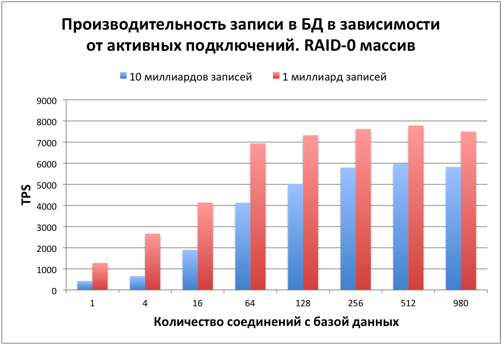
Скорость записи уменьшилась на 20-40%.
Падение производительности объясняется:
- Большим размером индексов
- Меньшей долей оперативной памяти от всего размера БД
Варьируем количество записей в таблице
После проведенных тестов стало интересно, при каких размерах БД дисковая система становится определяющим фактором. Исходя из предыдущих тестов количество одновременных подключений было выбрано равным 64. Shared_buffers = 2048mb.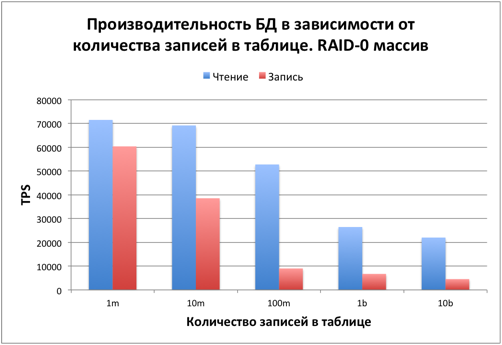
При количестве записей в таблице до 10 миллионов, данные полностью умещаются в оперативную память. Чтение и запись происходят быстро. В этом случае узким местом является процессор. Нагрузка по htop доходила до 100%. Во время тестирования около 20% процессора потреблялось Python-клиентом. Если клиент перенести на другую машину, то производительность будет пропорционально выше.
При 100 миллионах записей размер БД составляет около 6-7 Гб. Поместить БД в shared_buffers уже не получается, но при этом высокую роль играет дисковый кэш в оставшейся оперативной памяти. Примерно с таких размеров роль процессора становится менее значительной и на производительность влияет диск.
При 1 и 10 миллиардах записей в оперативную память помещается только незначительная часть данных и индекса. Узким местом является дисковая подсистема.
Стоит отметить, что данное тестирование синтетическое. Вероятность чтения каждой записи одинаковая. В большинстве реальных случаев в базе данных идет работа с небольшой долей записей от всего объема данных, поэтому будет больший выигрыш за счет их кэширования.
Резюме
Производительность БД на SSD RAID-0 массиве оказалась выше, чем на одиночном диске, но далека от линейного масштабирования. Если на данном железе требуется еще большая скорость работы, то лучше разделить данные на несколько баз данных и разместить их отдельно на каждом из дисков.В комментариях к первой части @MikeGav упомянул, что производительность SSD падает при заполнении диска. По ряду других тестирований SSD эта проблема наступает при заполнении на 85-90%. Во всех наших тестах общее место, занимаемое базой данных не превышало 75%. В следующей части будет тестирование производительности базы данных на SSD RAID-0 массиве в зависимости от настроек PostgreSQL.Пора провести финальные тесты и подвести итоги цикла статей. Сегодня мы рассмотрим влияние размера shared_buffers на производительность БД. Первые части можно почитать здесь и здесь.
В ходе развития сервиса оптимизации затрат на сотовую связь Dr. Tariff (iOS, Android) для совместного пилота с одним из партнеров нам потребовалась большая и производительная реляционная база данных.
Зависимость производительности БД от параметра shared_buffers
Параметр PostgreSQL shared_buffers задает максимальный объем оперативной памяти для кэширования на уровне базы данных. Количество записей – 10 миллиардов, количество активных подключений – 64, нагрузка на чтение. В этом тесте после изменения файла конфигурации происходил перезапуск сервера БД, поэтому перед измерением данных происходил тестовый запуск на несколько минут, чтобы кэш успел заполниться.
Производительность чтения практически не зависит от размеров shared_buffers. Размер БД в 40 раз выше, чем количество оперативной памяти в компьютере. При таком соотношении и использовании всего объема данных практически каждое чтение требует обращения к диску. В реальных ситуациях не следует пренебрегать этим параметром, так как Postgres будет кешировать наиболее часто используемые данные и таблицы меньшего размера.
Зависимость производительности БД от параметра fsync
В PostgreSQL есть параметр fsync, который отвечает за перенос данных из оперативной памяти на диск по завершению транзакции. По умолчанию он включен, и обеспечивает сохранность данных в случае сбоя. Сбой может быть вызван отключением питания, зависанием системы, сбоем в дисковой подсистеме... Если произошел сбой и fsync=on, то при очередном запуске БД данные будут востановлены. Если же сбой произошел, но при этом fsync=off, то скорее всего данные придется восстанавливать из последнего дампа. Отключение данного параметра позволяет существенно повысить скорость update и insert операций.
Производительность после отключения fsync выросла в 2-3 раза. Это очень хороший показатель.
Сравнение скорости SSD и HDD дисков
Для сравнения тестовая конфигурация была развернута на HDD диске. Скорость заполнения диска была в разы ниже в сравнении с SSD, поэтому тестирование было решено ограничить размером в 1 миллиард записей.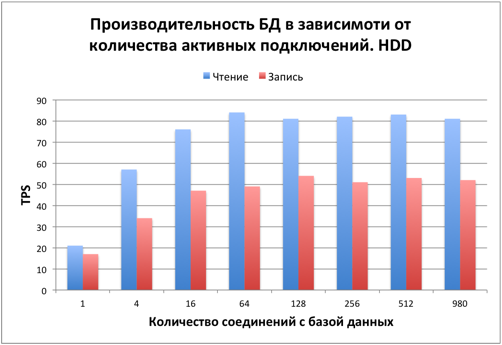
Как видим скорость работы БД на HDD диске замедлилась в сотню раз в сравнении с одиночным SSD при таком характере нагрузки. Подобная нагрузка требовательна к iops дисков. Iops для SSD и HDD как раз отличаются на два порядка. Для баз данных традиционно используется рейд массив из быстрых HDD дисков. Быстрые HDD диски имеют iops в 1.5-2 раза выше, чем HDD, который участвовал в тестировании. Еще в несколько раз можно увеличить скорость за счет рейд массива.
Резюме
Несмотря на все преимущества у SSD есть недостатки:- более высокая цена
- ограниченный ресурс на запись
Из данного тестирования и предыдущего опыта работы можем сделать следующие выводы:
- PostgreSQL хорошо работает с большими таблицами с количеством строк до 10 миллиардов и с количеством клиентов до 1 тысячи
- При размерах БД намного больше объема оперативной памяти и простых запросах производительность ограничивается дисковой подсистемой, а shared_buffers практически не влияет на производителность. Параметр fsync позволяет в разы увеличить скорость записи в БД.
- SSD диски имеют намного большую производительность применительно к базам данных, чем HDD диски и занимают свою нишу.
- SSD диски плохо масштабируются в RAID-0 массиве для случайного чтения. Если задача позволяет, то предпочтительнее использовать несколько баз данных на отдельных дисках, чем одну большую базу данных на RAID массиве.

